
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- pandas
- NLP
- 구현
- 지진대피소
- 자연어처리
- 너비우선탐색
- 코사인유사도
- dp
- 건축물대장정보
- 그래프탐색
- xmltodict
- 유사도
- 유클리드
- GroupBy
- Geocoding
- 공공데이터
- 분할정복
- 누적합
- 전처리
- TF-IDF
- 그래프이론
- 재귀
- 수학
- 우선순위큐
- cosine
- 백준
- geopy
- 비트마스킹
- 깊이우선탐색
- 그리디
Archives
- Today
- Total
정리용
[NLP] LSA (잠재 의미 분석 ), SVD ( 특이값 분해 ) 본문
1. SVD ( 특이값 분해 )
SVD는 행렬을 분해하여 중요한 요소만을 뽑아낼때 사용된다.
https://bab2min.tistory.com/585
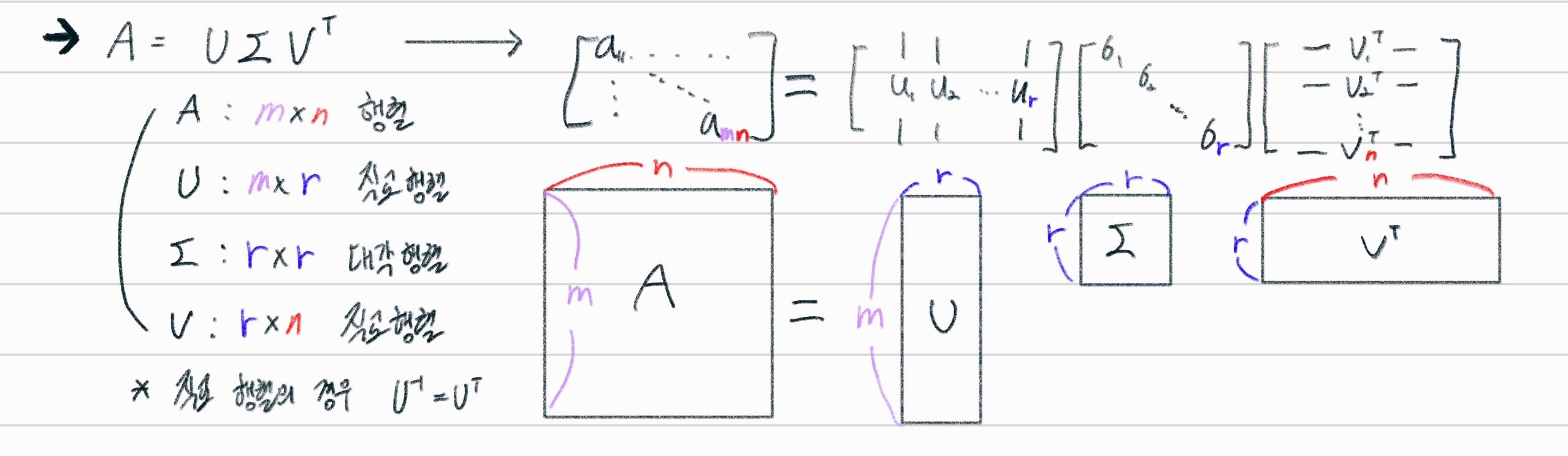
자연어 처리의 경우
U mertix => topic을 위한 word metrix 이고
Σ metrix => topic 에 대한 strength(강도)
Vt metrix => topic을 위한 Document matrix
여기서 Σ은 r개의 특이값을 가지는데, 이것을 작은 값으로 설정하여 topic strength 상위 r 개의 정보만 뽑아낸 형태를 truncated SVD 라고 한다.
Σ의 대각행렬의 원소들은 크기순으로 정렬되며 r = 1 이더라도 A의 shape는 계산된다
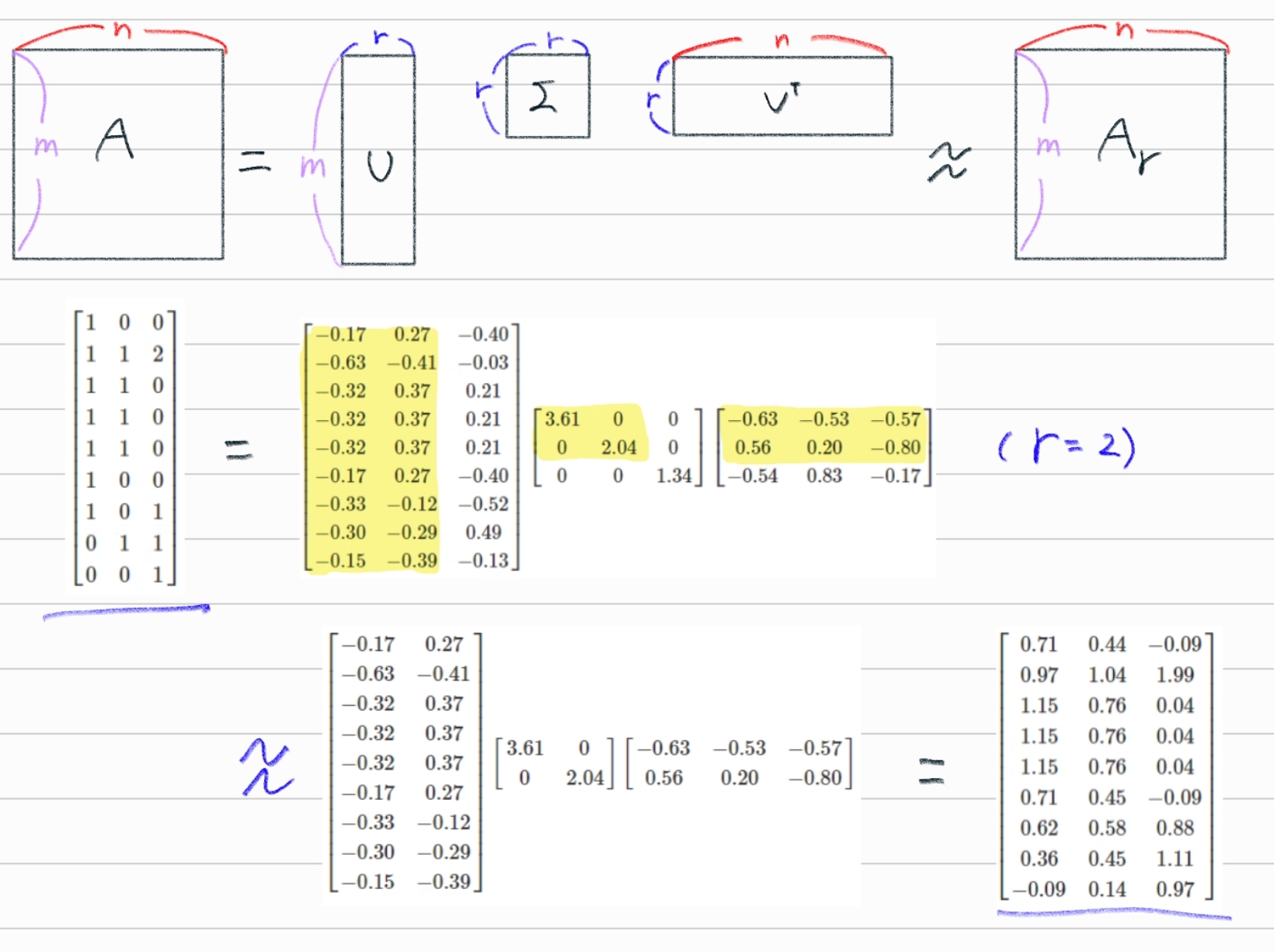
r = 2 의 truncated SVD를 적용해 Σ metrix 과 Vt metrix 의 차원이 3에서 2로 축소되었음을 행렬을 통해 알 수 있다.
2. 활용 방법
1. 단어 - 단어 간의 유사도
U X Σ metrix 의 row 간의 코사인 유사로를 이용
2. 문서 - 문서 간의 유사도
Σ X Vt metrix 의 colum 간의 코사인 유사로를 이용

3. 단어 - 문서 간의 유사도
U X Σ X Vt metrix 의 각 요소가 단어와 문서간의 유사도이다

4. 한계점
문서에 포함된 단어들이 정규분포(가우시안분포)를 따라야 적용이 가능하다는 점이다.
또한 문장이 추가 되었을때 새로운 단어가 있다면 처음부터 작업을 다시 시작 해야한다.
'딥러닝 > 이론' 카테고리의 다른 글
| [NLP] gensine을 이용한 word2vec 예제 코드 (0) | 2022.01.28 |
|---|---|
| [NLP] word2vec ( CBOW , Skip-gram) (0) | 2022.01.27 |
| [NLP] 문서의 유사도 측정 방법 ( 유클리드 거리 / 코사인 유사도 ) (0) | 2022.01.25 |
| [NLP] TF-IDF (0) | 2022.01.24 |
| [NLP] BOW ( Bag of Word ) (0) | 2022.01.21 |
'딥러닝/이론' Related Articles
more



Comments