
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- cosine
- 분할정복
- xmltodict
- 그리디
- 우선순위큐
- 구현
- 자연어처리
- dp
- 비트마스킹
- 백준
- 전처리
- 유사도
- 코사인유사도
- 유클리드
- GroupBy
- 수학
- 그래프이론
- 지진대피소
- 누적합
- NLP
- 그래프탐색
- Geocoding
- geopy
- TF-IDF
- 공공데이터
- 너비우선탐색
- 깊이우선탐색
- pandas
- 재귀
- 건축물대장정보
- Today
- Total
정리용
[NLP] BOW ( Bag of Word ) 본문
1. BOW 사용 이유
머신러닝을 사용하기위해 문장을 수치값으로 변환하는 자연어 처리의 가장 기본적인 방법이다.
2. 백터화 과정
2-1 단어사전
모든 문서에 대한 단어 사전(Vocabulary_ , 왼쪽 사진)을 생성한다.
모든 문장(text)에 대한 단어사전이 딕셔너리 형태로 생성된다.
이때 key은 문장에 나온 단어들이고 value는 빈도가 아닌 단어 사전에서의 단순한 인덱스이다
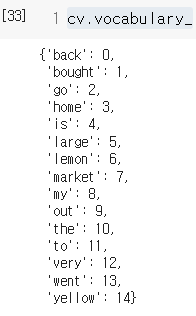
또한 n-gram 을 사용할 수 있는데 단어를 묶어서 단어사전을 만다는 것이다
예를 들어 n-gram의 range를 ( 1, 3 )으로 설정하면
back / back to / back to home / go / go back / go back to ... 와 같이 단어 사전이 생성된다.
2-2 빈도 기반 벡터화

생성된 단어사전를 인덱스로 하는 벡터가 생성된다
DTM(Doument Term Matrix)로 표현하면 다음과 같다

3. BOW의 한계점
bow는 간단한만큼 한계점과 단점이 명확히 존재한다.
첫번째로는 의미를 전혀 고려하지 못한다.
" Mr. Jo Biden is doing a good job. "
"The president of the United States has the best work ability. "
두 문장은 사실상 같은 의미이지만 빈도를 기반한 BOW 에선 전혀 다른 문장으로 판별되어 낮은 유사도를 가지게된다.
두번째는 문장의 순서를 고려하지 않는다.
" home run "
" run home "
두 문장 또한 다른 의미를 가지지만 BOW에선 순서를 고려하지 않고 벡터화를 진행하므로 같은 문장으로 인식된다.
세번째는 벡터의 차원이
문장이 많아지면 그만큼 단어사전도 많아져 벡터의 차원이 무수히 많아진다.
이는 머신러닝에서 기하급수적인 계산량 증가를 야기한다.
'딥러닝 > 이론' 카테고리의 다른 글
| [NLP] word2vec ( CBOW , Skip-gram) (0) | 2022.01.27 |
|---|---|
| [NLP] LSA (잠재 의미 분석 ), SVD ( 특이값 분해 ) (0) | 2022.01.26 |
| [NLP] 문서의 유사도 측정 방법 ( 유클리드 거리 / 코사인 유사도 ) (0) | 2022.01.25 |
| [NLP] TF-IDF (0) | 2022.01.24 |
| [NLP] 자연어 처리의 고전적인 방법 0 (개요) (0) | 2022.01.18 |


